今年5月に催されたCHI 2024の論文をAIに要約してもらってたくさん読んでいたのですが、要約ばかりも味気ないですし、少し気になった論文を深堀りして紹介しようかと。今年のCHIはやはり生成AI関連の論文が多いですが、生成AIはChatGPTなど一般の人にも身近になってきているので、内容も直感的にも分かりやすいものが多い印象でした。
「生成AIのデザインの固定化(あるいは固執)と発散的思考に与える影響」ということで、画像生成AIをデザイン作業の支援ツールとして使った際にどのような影響を与えるのかを検証した論文です。統計の話は少しありますが技術的な内容はあまり無くて、デザイン分野における実証実験結果の分析と共有です。論文中の頻出用語であるDesign Fixationは「デザインの固定化」と訳せると思うのですが、論文中でもネガティブなニュアンスで使われているので、日本語だと「固執」とわざとっぽく表現した方がわかりやすいかもしれません。日本では「固定観念」と訳してる人もいたようですが、その表現はちょっとニュアンスが違うと思うので注意しておきたいです。もちろんこのエントリーも僕の個人的解釈による意訳が含まれるので併せて注意してください。
課題設定
生成AIは人間の創造性を増強し、発散的思考を促すツールとして期待されているが、これらの主張に対する実証的証拠はほとんどない。画像生成AIを用いたアイデア発想課題の実験を通して、デザインの固定化(あるいはデザインへの固執)と発散的思考への影響の測定を行った。
Design Fixation(デザインの固定化あるいは固執): あるアイデアに触れることで、その後のアイデアに固定や偏りが生じ、デザイン空間の探索が制限される場合に起こる。固定化は経験に関係なく、また創造的な仕事のあらゆる領域で、意識的にも無意識的にも起こる。デザインの固定化が創造的なプロセスに与える深刻な悪影響は、デザイン研究における重要な関心事となっている。
実験結果
チャットボットアバターをデザインするというアイデアを発想するタスクにおいて、画像生成AIの支援を受けると、最初に提示された例に固執してデザインの固定化をもたらすことを発見した。画像生成AIを使用した参加者は、何も支援を受けずにアイデアを生み出したグループ(ベースライン)と比較して、アイデア数が少なく、多様性・独創性が低かった(定量指標は後述)。定性分析によると、AIと共同でアイデアを発想する有効性は、プロンプト作成へのアプローチと、参加者がAIの提案に対してどのような戦略を採るかということが重要である。
課題説明の際に提示されたデザイン例
![]()
実験参加者によって作られたデザイン例
A: 支援ツールのサポート無し、B: Google画像検索によるサポート有り、C: 画像生成AIによるサポート有り
![]()
以上はCHI勉強会や他個人ブログ等でも紹介されていた課題設定と結果の要約となりますが、なぜそうなったのか論文を読んで深掘りしてみます。結構長い論文でしたが、実験の具体的手順や評価方法などを補足を加えつつまとめます。
実験詳細
AIが生成した画像が、デザイン例を提示された後の視覚的なアイデア出しの際に、デザイナーの発散的思考にどのような影響を与えるか実験を行った。このシナリオをツールによる支援有りの場合と、ツールを使用しなかった場合とで比較した。独立変数を、支援なし(Baseline)、Google画像検索(Image search)、生成AI(GenAI)とし、従属変数を、Design Fixation Score (DFS) (各スケッチに例と共通する特徴の数)、流暢性(作成されたスケッチの数)、多様性(作成された異なるタイプのスケッチの数)、独創性(他の参加者が同じタイプのスケッチを考案する頻度がどれだけ低いか)とする。実験は、管理された実験室で混合法のアプローチに従って実施した。全ての参加者は、手順を説明した平易な文章を読んだ後、文書によるインフォームド・コンセント(内容をよく理解し、納得した上で参加すること)を行った。
課題説明の際に提示されたデザイン例
![]()
実験課題は、参加者が新しいチャットボット・アバターのアイデアを紙にスケッチして、できるだけ多く、異なるアイデアを考案するよう求められる視覚的なアイデア発想タスクとなる。画像検索(Google画像検索)と画像生成AI(Midjourney)を利用する条件の参加者には、それらの支援ツールを使って作品のインスピレーションを集めることができると伝えた。
この実験では、参加者(60名)間の独立変数として、タスク中に利用可能なインスピレーション刺激(Inspiration Stimulus、インスピレーションの源)を3段階で設定した。
- ベースライン:ツールによるサポート無し。
- 画像検索:Google画像検索を利用、ブラウザの履歴が結果に影響するのを避けるためシークレットモードからアクセスした。
- 画像生成AI:Midjourneyボット(プロンプトを入力し、モデルからの出力を表示するために利用)を実行するプライベートDiscordサーバーを通じて、画像生成AIツールであるMidjourney V4の有料版にアクセスする。参加者はテキストプロンプトを通じてMidjourneyと対話し、入力されたプロンプトごとに4枚の画像を生成してもらう
参加者について
デジタル掲示板、大学の学生サークルのメーリングリスト、口コミで60人の参加者を募集した。参加者は、デジタル登録フォームを通じて興味を示した。参加者は、ビジュアル・デザインの経験(年/月単位)を自己申告した。参加資格基準に基づいて参加者をスクリーニングし、18歳以上でビジュアル・デザインの経験がある人を電子メールで招待した。さらに、依存関係を避けるため、参加者の誰も、この研究を実施している主要研究者と直接のつながりがないことを確認した。参加者の平均年齢は25.8歳(18~49歳、SD=5.4)。参加者には、芸術、ビジネス、コンピュータサイエンス&IT、デザイン、工学、科学など多様な領域の学部生、修士課程修了者、博士課程修了者が含まれた。各条件の参加者数は同数で、男女のバランスもよく、1条件につき女性10名、男性10名(性別は参加者が自己申告)。
定量指標
4つの標準的な尺度(デザインの固定化、流暢性、多様性、独創性)についてそれぞれ定量化して評価する。
1. Design Fixation Score (DFS、デザインの固定化度合い)
コピーの度合いを測る、最初に見せたサンプルが持つ特徴と参加者のアイデアが持つ特徴がどのくらい重なっているか。
![]()
2. Fluency (アイデア数)
参加者によって生み出されたスケッチの数。制限時間20分内に各参加者が作成したスケッチの数をアイデアの数としてカウントする。
![]()
3. Variety(多様性)
提出された全てのスケッチ(N=277)に識別子を割り当て、実験内容を伏せた2人の評価者にスケッチをクラスタリング(グループ化)する作業を行わせた。下記計算式は、参加者のスケッチが全て同じクラスターに属していればスコアは0、全てのクラスターにスケッチがあればスコアは1となる。このグループ化作業では、外見、体型、付属物、形状、アクセサリーなどいくつかの要素が考慮され、結果として83のクラスターができた。
![]()
4. OriginalityあるいはNovelty (オリジナリティ・独創性)
オリジナリティは下記計算式で測る。同じクラスターに属するアイデアを持っていた他の参加者の数を数え、それを他の参加者の総数で割って1への補数を計算する。全て参加者が同じクラスタでアイデアを持っていた場合は0となり、1人の参加者だけがそのクラスタでアイデアを持っていた場合は1となる。
![]()
結果詳細
実験参加者によって作られたデザイン例
A: 支援ツールのサポート無し、B: Google画像検索によるサポート有り、C: 画像生成AIによるサポート有り
![]()
著者により理論化された因果有向非循環グラフ(詳細は実験詳細の項を参照)
![]()
このグラフはインスピレーション刺激(補足: ひらめきの源、本実験における「画像検索結果を見た」「AI生成画像を見た」のようなソースを指す)がユーザーのデザインの固定化、流暢さ、多様性、独創性に影響するという主張。何にインスピレーションを刺激されるかによって、スケッチ作業に費やす時間に影響し、その結果、生成されるスケッチの数(流暢性)に影響する。より多くのスケッチを作成することで、アイデア発想中により多くの領域をカバーする可能性も高まるため、流暢性が高いほど多様性も高くなる可能性が高い。スケッチの種類が多ければ多いほど、独創的なアイデアが生まれる可能性が高くなる。
↑の各指標間の関係性は統計分析において共変量として扱われそれぞれモデル化・適用されています。
結果の分析
デザインの固定化と発散的思考の定量的分析のためにベイズ統計モデルを構築し従属変数と独立変数の関係を定量化した。モデル構築にはbrmsパッケージを使用し、ベイズマルコフ連鎖モンテカルロ(MCMC)サンプリングプロセスの信頼性を確保するために、2つの指標(R-hat, Effective Sample Size: ESS)を通して収束性と安定性を評価した。
—-
僕は知らなかったのですがHCI分野においてベイズ統計を使った方が良いという理論的根拠は以下の論文でKayらによって提案されています。これを読んで理屈を理解できるか分からないですが時間を作って読んでみようと思います。
各定量指標のモデル化については、過去の関連研究を根拠としているものもあり、書くとだいぶ長くなりそうなので省略しますが、前述の各定量指標の計算式を見ればこの実験で測りたいことは容易にわかるかと思います。
以下はモデルの事後予測、エラーバーは推定値の標準誤差
1. Design Fixation Score (DFS)
![]()
画像生成AIおよび画像検索によるツール支援を受けた場合はいずれも最初のアバター例と共通する特徴をより多く描き、さらに画像生成AIは画像検索よりもデザインの固定化を起こすことを示唆している。
また、参加者による各スケッチのDFSとAI生成画像間のDFSとの間には中程度の正の相関が観察された(ρ = 0.56)。これは、初期デザイン例の特徴を含むAI生成画像が、より高いDFSを持つスケッチにつながったという考えを定量的に裏付けており、AIがアイデアの結果を決定する上で潜在的な影響力を持っていることが示唆された。
![]()
2. Fluency (アイデア数)
![]()
画像生成AIも画像検索もベースラインと比較して流暢性(スケッチのアイデア数)を増加させることは無く、むしろ両者ともアイデア数は少なくなった。
また、詳細は省略しますが、タスクに費やした時間(Time on Task)を考慮したモデルによる評価では、流暢性に対する画像検索の影響は最小であり(平均値 = -0.22、89%信用区間 [-0.64, 0.19])、対照的に、画像生成AIは流暢性に対する影響は小さい(平均=.10, 89%信用区間 [-.41,.60] )という結果になっています。89%という区間を使っているのは関連研究による理論的裏付けがあるようです。
3. Variety(多様性)
![]()
画像検索も画像生成AIも、ベースラインと比較して多様性を高めることは無かった。
補足: 流暢性(Fluency)を共変量として含むモデルについては、Google画像検索は多様性にあまり影響を及ぼさなかったが、画像生成AIの方はマイナスの影響を与えています。
4. OriginalityあるいはNovelty (オリジナリティ・独創性)
![]()
画像検索も画像生成AIも、ベースラインと比較してオリジナリティを向上させることはなかった。
補足: 多様性(Variety)を共変量に加えたモデルでも意味のある変化はなく、多様性はオリジナリティを媒介しない(影響しない)ことが示唆されています。
考察
画像生成AIを使ったアイデア出しが、なぜデザインの固定化(あるいは固執)を引き起こしたのか?
全体的な分析によると、参加者は、デザイン概要から直接コピーしたキーワードを含むプロンプトに頼るか、初期のデザイン例からインスピレーションを得たプロンプトを使用することが多かった。これらのプロンプトによってAIが生成した画像は、44%のケースでデザイン例と概念的に類似しており、デザイン例に存在する固定的な特徴を頻繁に含んでいた。画像生成AI利用者がプロンプトで使用した単語の頻度は以下の通り。
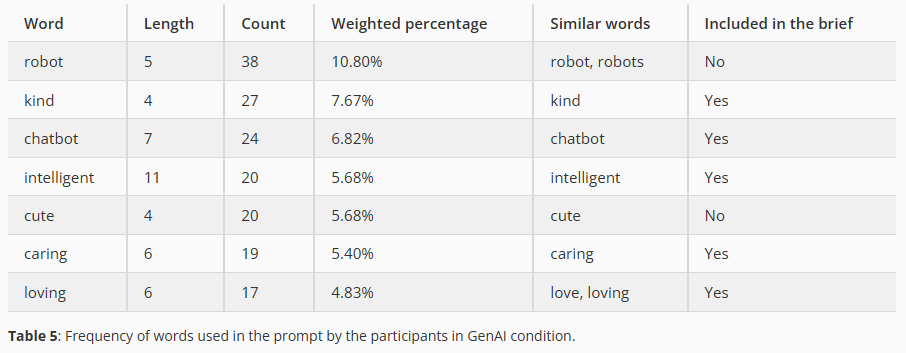
しかし、参加者がタスク概要にある単語やロボットに関連するフレーズを含まない39個のプロンプトを作成したことは注目に値する。例えば「親切で愛情深い」キャラクターという概念空間の中でさまざまな可能性を探ろうとしたり、「家族」というアイデアにたどり着き、関連性のあるプロンプトに変換したりした。
これらの事例を総合すると、タスク概要とデザイン例に基づいたプロンプトの作成が、デザインの固定化を招いていることがわかる。この問題を克服するためには、タスク概要とデザイン例を「超えて」考えようと試みることだった。
Fixation Displacement (固定変位と訳してみます)
AI画像に基づいたアイデアの発想は、参加者がAIによって生成された画像を模倣してしまう固定変位に繋がる可能性がある。参加者がデザイン例とはほとんど関係のないスケッチを描いているのにもかかわらず、客観的にも主観的にもAI画像への高度な固着(とても類似している、コピーしている)を示している。
以下の図は固定変位の例を示している。ここでは、参加者はアイデアを考え始める方法として「女神」というプロンプトを入力した。このプロンプトは、デザイン概要やロボットアバターのアイデアとはほとんど関係がない。その後、参加者は女性の顔のスケッチを描いた。このスケッチは、例のロボット・アバターと少数の特徴(目、口、耳)を共有しているが、質的に異なっている。つまり、参加者が最初のデザイン例からフォーカスをずらしたとしても、代わりにAIが生成した画像にフォーカスを移されたことになる。

AIによって生成された画像は、忠実度、視覚的詳細度、品質、形状、形態、質感、色彩、構図、視覚的表現力に富んでいるように見えた。つまり、AI生成画像がとても高品質であることにより、適合性を増幅させ、固視変位を引き起こした可能性がある。
注意点
先行研究に基づいてタスク時間を20分に制限したため、我々の洞察の範囲がこれらのツールの短期的な使用に制限されている。実世界の設定では、タスクに時間を費やすこと(スケッチなど)とインスピレーションを求めること(AIとの対話など)のトレードオフを考慮することが重要である。
また、参加者の中にはプロの業界経験者はほとんどいなかった。従ってこの研究では、初心者デザイナーがデザインタスクにどのようにアプローチするかについての最初の洞察を提供できるに過ぎず、これらの主張を一般化するには、さらなる調査が必要である。
おわりに、個人的感想
理論的な裏付けによって説得力を上げるためにいろいろ難しいことも書かれてましたが、論文を読む前から結論を先に知っていたので、実験参加者が描いたデザインを見れば直感的に一目瞭然という印象を受けました。本論文で扱ったモデルの解釈については僕のベイズ理論への理解度が浅いのでなんとなくしかわかりませんでしたが、著者は統計的な有意性を主張しているわけではないということなので実験結果の解釈には留意しておきましょう。今回は創造性の観点で運用された実験であり、その実験の制限時間が20分ということもあるので、実際の現場で適用するには、適切な時間設定を行いつつ、創造性以外にも例えば生産性の観点で運用してみるとまた別の考察が得られそうです。
そもそも昔からデザインの現場において、コンセプトデザインはアウトプットを制限する一連のアイデアやコンセプトへの盲目的な固執が見られるということが昔から言われていたらしいですし、今回の画像生成AIを使った実験でもそれが実証されたよということなのでしょう。
DFSの相関とFixation Displacement(固定変位)の考察にもありましたが、いくら人間側が独創的な発想からスタートしたとしても、固定変位によってAIが提供する例に置き換えられてしまうというまぁなかなか恐ろしい現象が起こってしまうようです。ただ、その脆弱性が明らかになったのであれば対策はいろいろ考えられるとは思いますし、エンジニアリング的なアプローチでAIによる置き換えを防ぐシステムを構築することも可能でしょう。
個人的には生成AIが人間の発散的思考を促してくれるという意見は変わっていません。目的が問題解決なのかアイデア創造なのかでプロンプトエンジニアリングの難易度も違うし、それによって生成結果への信頼性(精度)も変わります。画像生成AIに関する訴訟では、人間による創造的寄与があったかどうかが争点になってますが、この実験においては参加者の創造性がそのままプロンプトを介して結果に反映された結果だとも思います。
また、論文の主張それよりも、この分野の先行研究をたくさん知ることができたのは個人的な収穫でした。論文中にも先行研究の引用が大量にあったので、行間が繋げにくくて正直理解も浅くなりがちだったのですが、HCI分野への個人的興味を一層強くしてくれる論文でしたので読んで良かったです。
ところで、なんと来年のCHI 2025はパシフィコ横浜で開催されるらしいです。そこなら東横線でも車でも1時間以内なのでぜひ参加してみたいと思います。